
Source: artifical ointelligence technical readiness - Bing images
Organisations across the globe are embracing the new dawn of the 4th revolution. Embedding AI into business practices and operations is becoming more mainstream and seen as a necessity to maintain competitive advantage. Technical readiness requires an organisation to evaluate its eco-system, data, infrastructure (both operationally and culturally) and decision-making capacity.
Understanding the AI Eco-system

Source: ai eco system - Bing images
Before implementing or adopting an AI project, it is important for an organisation to understand its eco-system, i.e. its network of technologies both internally and externally. Eco-systems typically comprise of internal users, and external stakeholders, such as supply chain partners, IT providers, financial organisations, customers. This list is not exhaustive, and the composition is ever-changing and expanding due to the dynamic nature of AI and its capability potential.
Fundamental to understanding an ecosystem that is AI-ready are 3 key attributes:
1. Openness: Ecosystems require sustained attention and a concerted effort to develop and grow. McKinsey Group researchers assert that an organisation that is seeking to utilise an ecosystem effectively must develop “next-generation integration architecture to support it and enforce open standards that can be easily adopted by external parties.”
2. Flexibility: AI systems should be flexible, segmented, and easy to incorporate if they are to operate successfully. Kevin Martelli, KPMG MD for Data & Analytics, suggests that, due rapid changes in the marketplace and new emerging technologies, organisations need to construct ecosystems in what he calls a “layer and open manner”, i.e. a staged and incremental approach to support the system’s development and growth.
3. Interchangeability: Standardisation and compatibility are key to interchangeability and enhanced e coordination of cross-functional work efforts. However, it should be noted that some fear that such an approach can impede innovation.
Technology Readiness Scale
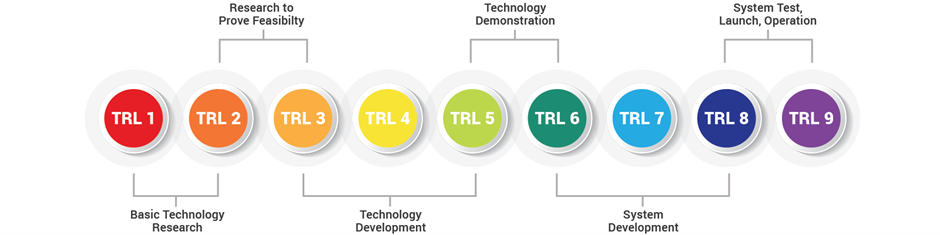
Source: technology readiness scale - Bing images
Prior to adopting AI, organisations need to undertake a technical readiness evaluation to assess ready state for integration. Harnessing the benefits of AI is as much about the technology itself as it is about organisational readiness state. Technology readiness levels (TRL) are a method for understanding the technical maturity of a technology during its acquisition phase. TRLs were first developed by NASA in the 1970s and are commonly used by engineers to provide a measure of technology readiness throughout its research development and deployment phase progression.
TRLs can be used to assess the readiness state for integrating and embedding AI into organisation infrastructures. There are 9 in total TRLs, moving form level 1 at basic principles observed to level 9 actual system proven in operational environment. TRLs have been used across many different sectors both private and public to evaluate and measure the effusiveness of system design and integration.
TRLs 4 to 7 are frequently referred to as the ‘valley of death’ as organisations often fail to recognise and prioritise the level of investment required to enable system maturity. The airline sector has worked consistently with a range of other sectors including the car manufacturing sector to bridge this gap and find the necessary solutions for success to progress past TRL 7.
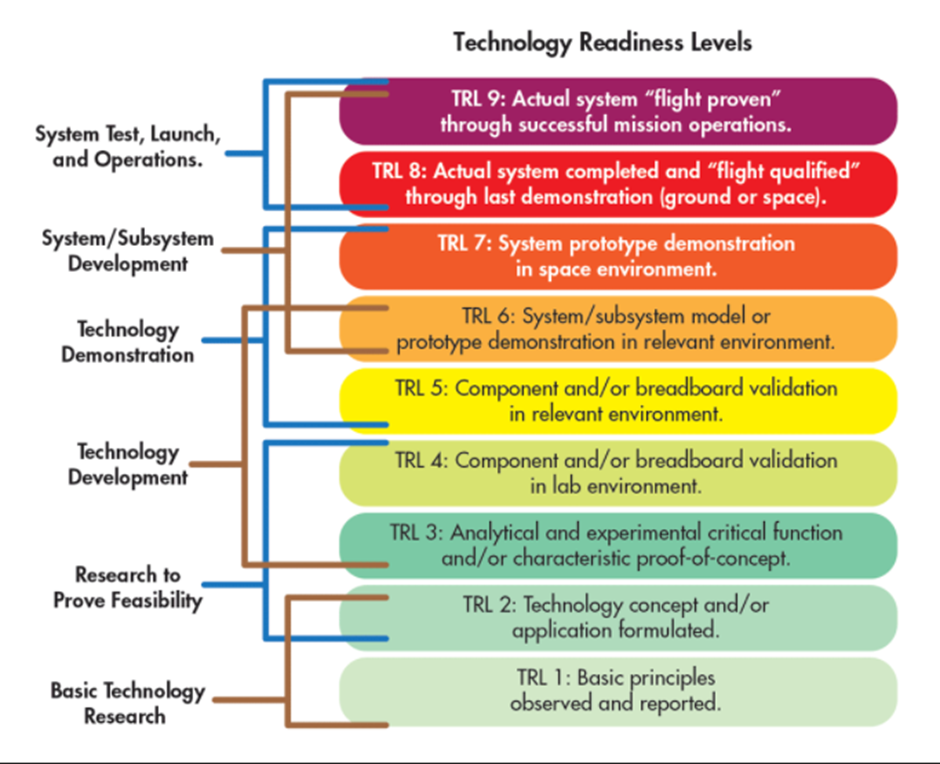
Source: technology readiness levels - Bing images
Technical readiness for AI integration can effectively use TRL to enable consistent, uniform discussions of technical maturity across different technology. Levels 1-3 represent the research phase, 4-6 the development phase and 7-9 the deployment phase.
The classification of the TRL defines the state of development for wide production and application, providing an indicator of potential success and readiness level. Assessment of TRL indicates to the markets and consumer readiness of the process or technology for wide market implementation. This is necessary before high levels of investment are made. Knowledge of the TRL makes it easier for developers and potential investors to monitor progress of research and the choice of technologies that are most ready for industrial application.
Source: Technology Readiness Levels I FENIX TNT - YouTube (0:06-2:08)
OR
Information Architecture
Source: https://www.google.co.uk/url?sa=i&url=https%3A%2F%2Fblog.prototypr.io%2Fthe-comprehensive-guide-to-information-architecture-29b09695fbcb&psig=AOvVaw1DLfw1cBkuOhBFFJOyW8vE&ust=1646499787499000&source=images&cd=vfe&ved=0CAsQjRxqFwoTCIi7hvX3rPYCFQAAAAAdAAAAABAD
It is imperative an organisation has full visibility and understanding of current data profiles, storage and usage. Information architecture (IA) is critical to understand before organisations flood their system with more information. AI benefits are gained through adding value, not complexity and confusion.
‘There is no AI without IA’ (Earley, The AI powered Enterprise, 2020)
Without a clear blueprint of the current data infrastructure, an AI system is likely to evolve in a fragmented manner that limits the realisation of any impact or benefits. Organisations need to conduct a comprehensive overview of all data and be clear as to what and how the data is generated, used and stored. Earley in his book ‘The AI Powered Enterprise’ (2020) suggests organisations should look at how data is used, and then develop systems for organising and categorising the data.
AI calls for a particular type of data to work with, and as such, organisations must create and develop a data environment that supports accessibility and availability. Information architecture systems should be capable of integrating the insights generated back from AI into decision making processes. This can be complex in large, widely distributed organisations and why, before adopting AI solutions, it is imperative that the information architecture is blueprinted and rationalised thus safeguarding that data points are in the right locations and for the right purposes.
Organisations must create and develop a data environment that supports accessibility and availability.
A key enabler for AI technical readiness is having sufficient computing power, whether on premises or in the cloud. An Accenture survey of 1,500 senior managers found that “76% understood that being able to scale was crucial to their success with AI but also believed they would struggle to make that happen”. Organisations can fall into the trap of thinking that the cloud is sufficient, however this may not always be the case. They should be cognisant of current capacity and capabilities and have acquired a requisite understanding of how to scale, and so augment resources as required to accommodate a growth in work.
Real time models that are adopted to enhance customer experience demand speed, and as such, generate algorithms with sufficient power so as to maintain customer interest and engagement. Failure to have the velocity and computing power behind the AI will lose current and potential customer interest which will be drawn elsewhere. Providing the scaling opportunities associated with computer power can be a challenge for smaller organisations and thus can prohibit the full benefits from AI. As such, ‘off-the-shelf’ or outsourced solutions may be the most beneficial resolution for this issue.
The infrastructure must be modular to facilitate the integration of new AI applications and have a high capacity for AI-related data-intensive training and testing procedures. The focus must lie on developing 3 underlying infrastructure capabilities for AI:
1. data storage capabilities to generate and store large amounts of data
2. networking capabilities to access, process, and transport data quickly
3. scalable computing power capabilities to handle AI workloads
Data readiness

Source: https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQg0T9UQYwn52TMgGLBVRn9pi8elAMO0Kfmxg&usqp=CAU
Technical readiness also refers to the acceptability of the existing data to integrate with the proposed AI solution and so empower effective decision making. Identifying and utilising the correct data is critical for successful AI adoption and a prerequisite for any AI project; more so, it is crucial that the data is context-specific and tailored according to the related domain, i.e. a specific technology (Molla and Licker 2005). To maximise potential output, data must be suitable in terms of quantity, depth, balance, representation, completeness, and cleanliness.
To maximise potential output, data must be suitable in terms of quantity, depth, balance, representation, completeness, and cleanliness.
There are 4 key areas that require careful consideration to enhance an organisation’s data readiness.
1. Data availability: AI-based systems learn through different data types and large data volumes. These fuel AI solutions that aim to create accurate projections. Structured data is standardised for AI applications and thus easier to use, whereas unstructured data, such as audio, video, or image files, are utilised in more sophisticated AI applications and scenarios. It is crucial that an organisation determines the appropriate data type and quantities required.
2. Data quality: Different quality dimensions verify the suitability of the data for use by data consumers. Improving on these quality dimensions augments AI readiness levels. AI-relevant data quality dimensions include completeness and accuracy. Historical data often poses data quality issues for organisations so focus should rest on efforts to improve on universal capabilities such as data preparation, data processing, and data quality assurance.
3. Data accessibility: To support AI personnel in their roles, quick and easy access to relevant data sources is needed. It enables them to easily model and develop AI solutions and is facilitated by controlled access management. Data accessibility might also be simplified by exploiting data centralisation measures (e.g. creating a data lake or warehouse) rather than storing data in dispersed data silos.
4. Data flow: Smooth and automated data flow between its origin and use ensures high data accessibility to AI personnel and facilitates the implementation and maintenance of AI systems. Indicators for good data flow include:
i. defined extract-transform-load processes
ii. established data pipelines
iii. continuous and automated data streams
(Catalyst Fund 2020)
However, AI adopters must be aware that issues relating to data management and data readiness continue to be a concern. Cleaning inaccurate or disparate data is a burdensome process, with organisations typically spending 6-12 months doing so; the later this happens in the process, the more significant the associated costs will be. Furthermore, recent studies by Deloitte found that at least 40% of adopter organisations indicated “low” or “medium” levels of sophistication across a range of data practices, and almost a third of senior managers identified data-related challenges as one of the top 3 concerns hampering their company’s AI initiatives. Evidently, it is still an exploratory and experimental process for many companies.’